
Random Forest In Machine Learning


INTRODUCTION
We learnt how decision trees operate in the last post, but the issue was that they have a tendency to overfit. However, is there a situation where decision trees can be used to achieve even better outcomes? Indeed, my friend, there is an algorithm called Random Forest that generates a final prediction by utilizing several decision trees. We'll learn about ensemble learning, which is a sort of learning in which several algorithms are used to improve predicted performance.
Introduction to Random Forest
Random forests are an ensemble learning method for classification, regression, and other tasks that operates by constructing multiple decision trees at training time. For classification tasks, the output of the random forest is the class selected by most trees.
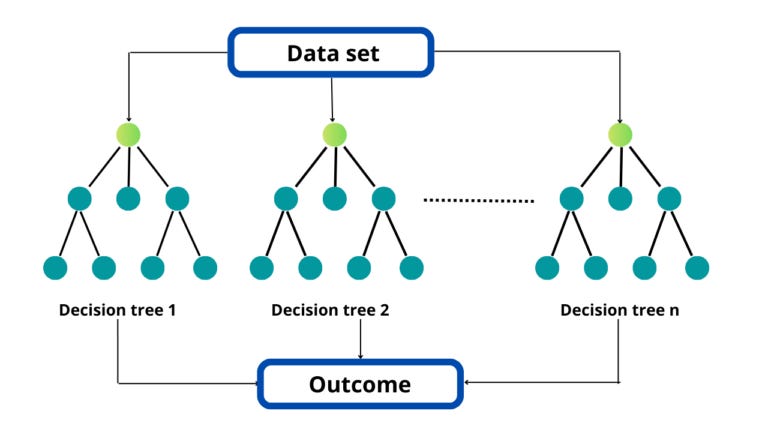
Intuition
As an example, let's say that there is a lockdown and that all lessons and exams are now conducted online. In order to make the paper challenging, the teachers let the students assist one another. John, our main character, attempted to join the company of bright pupils, but they refused to let him in. John, poor guy. However, John is realistic, so he formed his own study club of typical students, which he named Examgers, and came up with a study schedule to finish the exam's syllabus.
Each and every student studied hard but on the day of the exam, the paper was quite a bit hard making it difficult to verify if one’s answer is the correct one. So they came up with a strategy, a brilliant one. They decided that everyone will attempt the same question and the answer that was in the majority will be the correct one. For example, If the question is fine if 256 is a perfect square then every member of Examgers will solve it and give their answers, and the answer given by the majority will be the final answer.
Let’s say 4 people said yes 256 is a perfect square and 2 said no it isn’t then the final answer would be Yes since it was decided by the majority. In the end, John’s group performed very well and the faces of intelligent students were a sight to see.
The way that John’s Group gave the exam is quite the same as that of the working of Bagging. Let’s understand bagging more in-depth.
Therefore, in the earlier articles, we showed how different methods may be used to predict a class and provide the corresponding properties of that class. An ensemble learning method called bagging integrates the learning of several models to improve the overall performance. It enhances model stability and lessens overfitting. There are two steps involved in bagging: Aggregation and Bootstrapping.
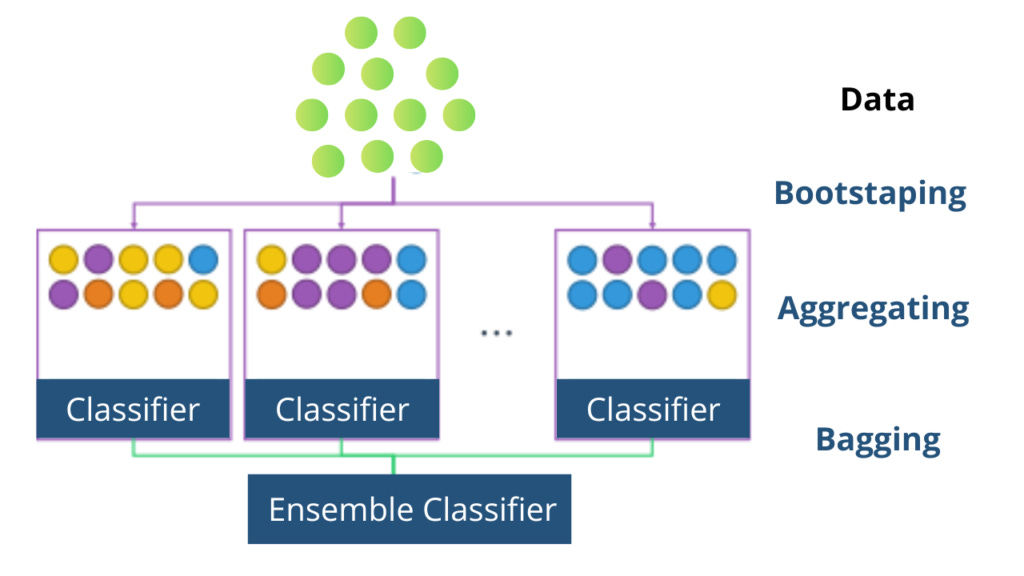
Bootstrapping
A technique called bootstrapping allows us to take a larger sample and turn it into several smaller samples. It should be noted that the smaller samples are produced by randomly selecting data points and repeating them, which may involve sketching the same data point more than once.
Assuming that N smaller samples have been produced, the next step is to develop N models and train them on the matching samples. As an illustration, suppose we have three models (M1, M2, and M3) and N samples (S1, S2, and S3). Next, M1 will be trained on S1, M2 on S2, and M3 on S3.
Now we have our trained models, but how do we combine their learning? After all, when given testing data each model may provide a different answer. That’s what aggregation is all about. Let’s take a look.
Aggregation
So let’s say we have testing data, t, and we predicted its class using our trained models. When predicting the class of testing data M1 predicted class 0, M2 predicted class 1, and M3 predicted class 0. Now we’ll take the max voted class i.e. class 0 as the final answer. This is the case for classification i.e. we take the max or majority voted class as the prediction of the ensemble model. In regression, we’ll take the average of all the predictions provided by the models and use that as the final prediction.
Working of Random Forest
With one additional change made in the Bootstrapping process, Random Forest now functions similarly to Bagging. Subsamples are used in bootstrapping, but the number of features stays the same. However, we also choose characteristics at random for the smaller sub-sample in Random Forest. Assume we have 1000 data points and 6 features (f1, f2, f3, f4, f5, f6).
we create 3 smaller samples that look like this:-
Sample 1: –
Features: f1, f2, f3
No. of rows: 500
Sample 2:–
Features: f1, f3, f6
No. of rows: 500
Sample 3:
Features: f2, f4, f5
No. of rows: 500
Now we’ll train 3 decision trees on these data and get the prediction results via aggregation. The difference between Bagging and Random Forest is that in the random forest the features are also selected at random in smaller samples.
Random Forest Using Sklearn
Random Forest is present in sklearn under the ensemble. Let’s do things differently this time. Instead of using a dataset, we’ll create our own using make_classification in sklearn. dataset. So let’s start by creating the data of 1000 data points, 10 features, and 3 target classes.
#loading the dataset
from sklearn.datasets import make_classification
X, Y = make_classification(n_samples = 1000, n_features = 10, n_classesNow that we have our training and testing data let’s create our RandomForestClassifier object and train it on the training data. To train the data we use the fit() method like always. Let’s do it.
# Importing the RandomForestClassifier class
from sklearn.ensemble import RandomForestClassifier
#loading the data into the model
clf = RandomForestClassifier()
clf.fit(x_train, y_train)Let’s make a confusion matrix for our predictions. You can find confusion_matrix in sklearn. metrics.
#Importing the confusion_matrix method
from sklearn.metrics import confusion_matrix
#Displaying the confusion matrix
print(confusion_matrix(y_test,clf.predict(x_test)))Output:-
[[92 5 3]
[ 3 96 1]
[ 4 8 88]]Advantages of Random Forest Algorithm
It reduces overfitting in decision trees and helps to improve the accuracy
Works well for both classification and regression problems
This algorithm is great for a baseline model.
Handles missing data automatically.
Normalizing of data is not required.
Disadvantages of Random Forest Algorithm
Computationally Expensive in random forest algorithm.
This algorithm takes time in fitting to build multiple decision trees.
Thanks for reading.
 | A guest post by
|